Omnidirectional Image-Based Navigation
My main (unpublished) research project at ETH was in my area of interest: robotic navigation in unknown environments.
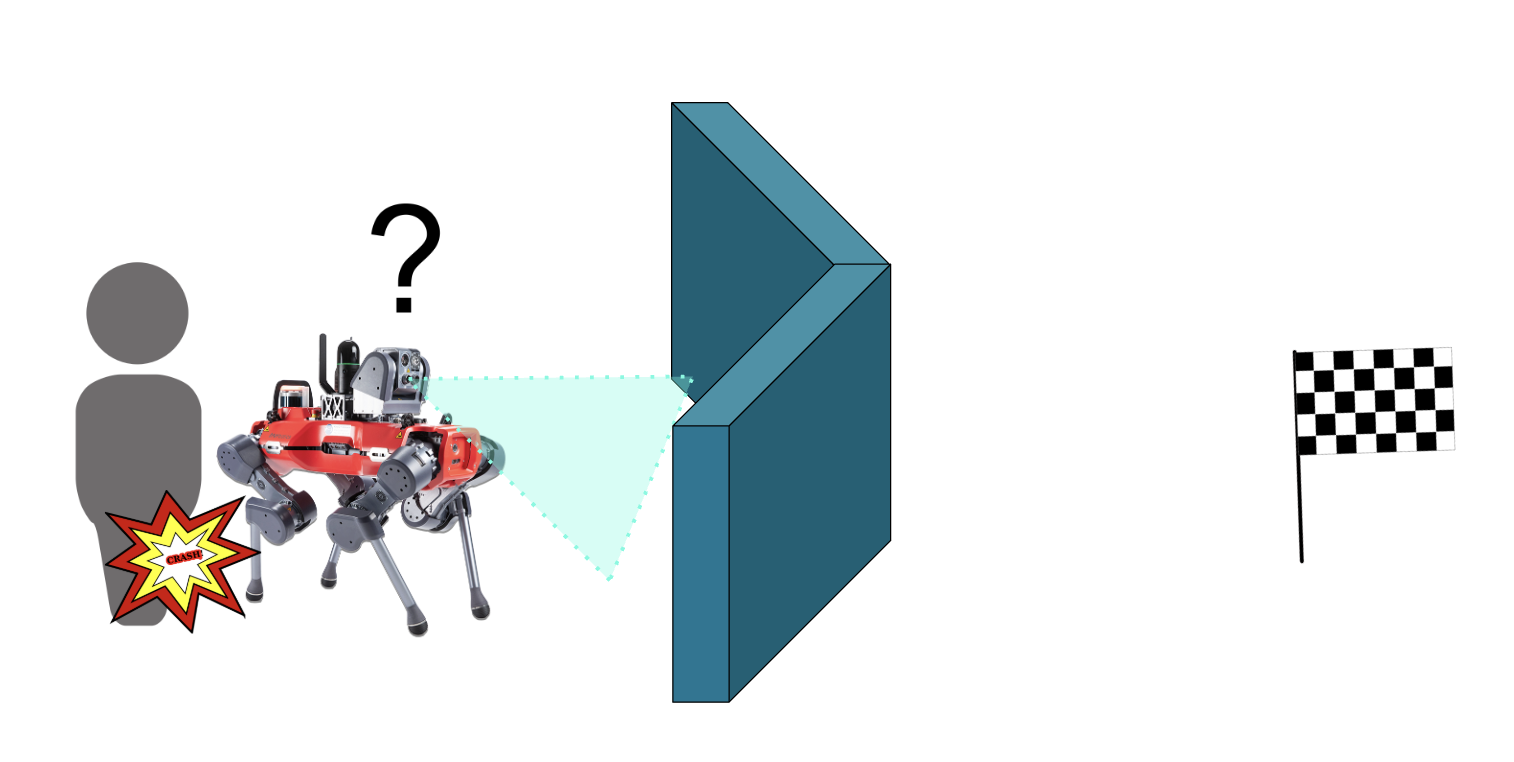
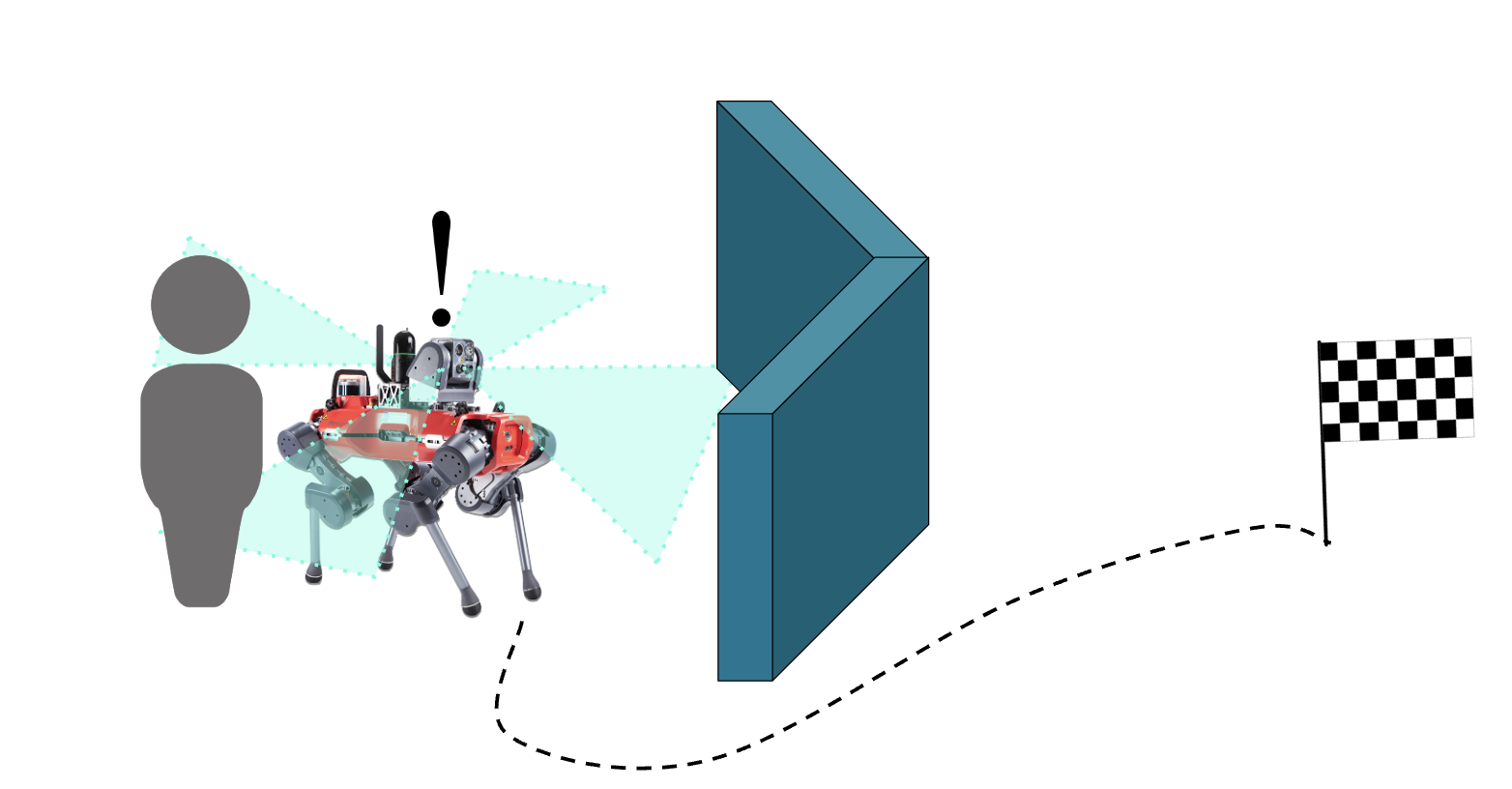
A common issue in robotic navigation is what’s called “local minima”, which is just lingo for dead ends, or even just concave obstacles. Robots can get stuck in them, and giving them the ability to reason about how to escape — and not just re-enter them again — is a big open question.
This project explored how we might be able to use several cameras with an omnidirectional view around the robot instead of the usual single front-facing camera, in order to give the robot more data to reason about to escape these traps, without having to code in complicated structures for memory.

Pre-Training Pipeline
* end-to-end RL means that you put all the raw sensor data into your RL model, have it spit out commands for your robot, try out those commands, and reward or punish the model depending on whether they are successful. You try this many times across many scenarios and eventually your model learns what the best commands are for any sensor data it receives. It’s very analogous to the way humans learn and is a popular idea in robotics.
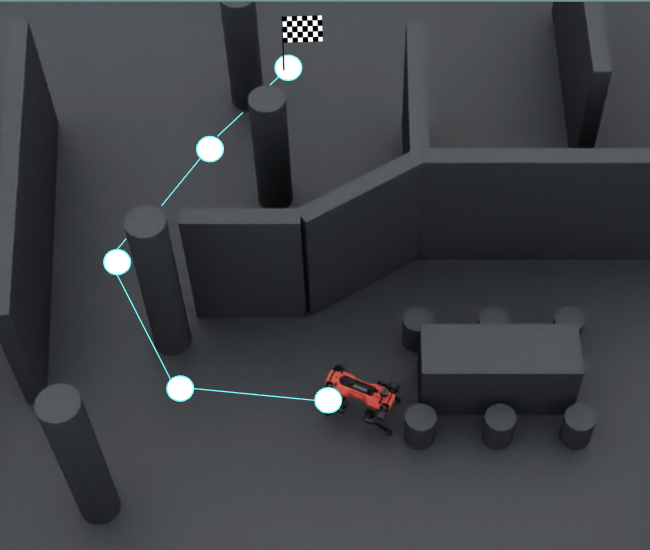
The project was successful, but only tested in simulation — which is miles away from working in real life. Just look at the circular image showing what the simulated environment looks like, and imagine a robot trained to navigate there trying to move about the complexity of the real world. Because of this shortcoming and running out of time to pursue it further, I didn’t move to publish my work, but you can read the report on the project, or use the library I wrote to project imagery from arbitrary camera reference frames to an egocentric sphere.
Although cameras are cheap and are a rich source of data, using them in Reinforcement Learning-based approaches to robotic control is hard because they produce a lot of data. Much too much to feed into your RL pipeline raw and have it train end-to-end*, so you need to work out how to represent your images as something downsampled in a way that retains useful data for navigation.
This project used a pre-training pipeline where it trained a Vision Transformer (ViT) to compress the raw spherical imagery down to a smaller representation trained to concentrate on features in the image that were relevant to finding a navigation goal.
Then it froze the ViT part of the pipeline, so that it would just be used to perform the compression it had learned, but not improve at it anymore. In this mode it was lightweight enough to be used to process incoming camera data for a robot in simulation to learn to navigate using RL.